Encore, JavaScript! Create an MP3 reader with DataViews + TextDecoder.
This post first appeared on the Big Nerd Ranch blog.
Check out the finished code on Github.
Like all good blog posts, this one started with a conversation on Twitter. Giovanni Cortés showed off an elegant snippet of Elixir code that leverages destructuring to parse the song metadata (title, author, etc.) from an MP3 audio file.
About this time I was brainstorming new topics for our web development guide about JavaScript’s high-performance data types. Although JavaScript’s destructuring isn’t as extensive as Elixir’s, it has great APIs for efficiently operating on large chunks of binary data.
While reading the tweet, I was also enjoying my favorite orchestral piece—Snöfrid, a beautiful melodrama by the Finnish composer Jean Sibelius—over coffee. So what could be more appropriate during a caffeine high amongst Scandinavian decor than to create an MP3 metadata reader with JavaScript?
Getting Started
To compose this masterpiece, we will use some standardized APIs available in both the browser and Node. For simplicity we will build a command-line tool with Node, but apart from reading in a file, the code will run as is in the browser!
MP3 metadata, like the song’s title and composer, is stored in a format called “ID3” at the beginning (or end) of an MP3 file. We’ll just pretend it stands for “MP3 information” since the acronym’s true origins seem mysterious.
There are several revisions of the ID3 spec. Giovanni’s lovely Elixir example extracts ID3v1 metadata (called “TAG”) from an MP3 file. The TAG spec is incredibly straightforward to parse since it uses fixed length fields. Unfortunately, it turned out to be too simplistic, so most of the MP3s in your music library use the much more flexible (and complex) ID3v2.3.0 spec. This version supports arbitrary length metadata and internationalization via alternate text encodings.
If you’re interested in seeing an ID3v1 reader, check out this implementation by Eric Bidelman. His example uses the jDataView library, which adds some nice (but non-standard) methods to the DataView API.
We are going to tackle the ID3v2 spec, so our JavaScript MP3 reader won’t be an apples-to-apples comparison with the Elixir example, but meanwhile we will explore a few more Web APIs!
Let’s set up the Node project:
# Create project directory
$ mkdir mp3-reader && cd mp3-reader
# Init package.json with defaults
$ npm init -y
# Install TextDecoder polyfill
$ npm install --save text-encoding
# Create main file and make it executable
$ touch index.js && chmod u+x index.js
Reading in a File
First off, we need to read in a file. In index.js, we’ll use the core fs library to asynchronously read in the specified MP3 file. This is the only Node specific code—after you read in a file, everything else will work in the browser!
#!/usr/bin/env node
let fs = require('fs');
const file = process.argv[2];
fs.readFile(file, (err, data) => {
});
Since this is an executable file, the first line—called a “shebang”—instructs the shell to execute this script with the Node interpreter. Now we can run it in the terminal:
./index.js fixtures/sibelius.mp3
When we execute index.js, process.argv will look like this:
[ '/Users/jonathan/.nvm/versions/node/v6.10.0/bin/node',
'/Users/jonathan/projects/mp3-reader/index.js',
'fixtures/sibelius.mp3' ]
process.argv is an array of at least two items: the full path to the Node executable and the full path to index.js. Any extra arguments passed to our script will begin at index 2, so process.argv[2] will be the path to the MP3 file we should read.
The fs.readFile() method accepts a callback, which will be invoked with an error argument and a Node Buffer object. Buffers have been around for a while, but they are specific to Node—you won’t find Buffers in the browser. However, Node has switched the underlying implementation of Buffer to a standardized JavaScript datatype: ArrayBuffer. In fact, Buffer objects have a .buffer property which returns the underlying ArrayBuffer!
ArrayBuffers are a performant way to store large chunks of data, especially binary data. You’ll find them in graphics APIs like WebGL and in multithreading. Since they’re part of the core language library, you can use ArrayBuffers in both Node.js and the browser!
To grab the Node Buffer’s underlying ArrayBuffer, we can destructure the data argument, which contains a Node Buffer, to extract just its .buffer property:
...
fs.readFile(file, (err, data) => {
if (err) { throw err; }
let { buffer } = data;
});
This fancy destructuring syntax is equivalent to let buffer = data.buffer. Now we’re ready to do the actual parsing!
Parsing the ID3 Header
ID3v2 metadata comes at the beginning of the MP3 file and starts off with a 10 byte header. The first 3 bytes should always be the string ID3, followed by 7 more bytes.
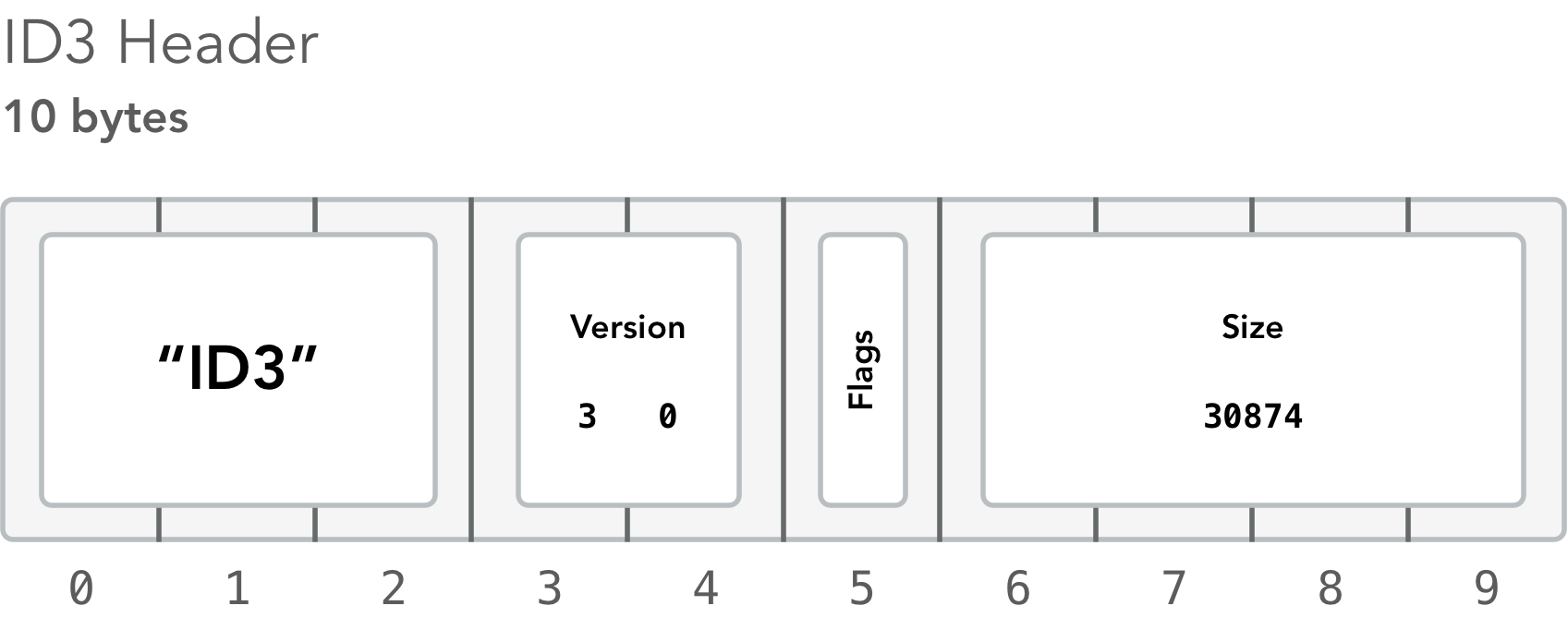
The first two bytes after ID3 (bytes 4 and 5) are version numbers. However, we can’t directly access the data in an ArrayBuffer: we need to create a DataView object to “view” that data.
...
const HEADER_SIZE = 10;
fs.readFile(file, (err, data) => {
...
let header = new DataView(buffer, 0, HEADER_SIZE);
let major = header.getUint8(3);
let minor = header.getUint8(4);
let version = `ID3v2.${major}.${minor}`;
console.log(version);
});
DataViews do not contain the data themselves, but they provide a “window” to “peer” into an ArrayBuffer. This means you can create multiple DataViews for the same ArrayBuffer—a clever design pattern for referencing the same chunk of memory with a different lens.
When creating a DataView, we specify the byte offset of where we want the “window” to start and how many bytes afterwards should be visible. While these two arguments are optional, they prevent us from “peering too far” and will throw useful exceptions if we attempt to access anything beyond these specified boundaries.
To grab the ID3 version numbers, we used the .getUint8() method. This method reads a single byte at the specified position relative to the DataView’s offset. In this case, it reads bytes 3 and 4 relative to an offset of 0.
The ID3 metadata section can be fairly long, so next we need to know the ID3 metadata’s total size (in bytes) so we don’t read too far and begin parsing the actual MP3 audio data.
...
let synchToInt = synch => {
const mask = 0b01111111;
let b1 = synch & mask;
let b2 = (synch >> 8) & mask;
let b3 = (synch >> 16) & mask;
let b4 = (synch >> 24) & mask;
return b1 | (b2 << 7) | (b3 << 14) | (b4 << 21);
};
fs.readFile(file, (err, data) => {
...
let size = synchToInt(header.getUint32(6));
});
Quite a bit going on there! Let's break this down. We read a 32-bit integer (4 bytes) starting at offset 6 (bytes 7–10) of the header that tells us how long the rest of the metadata is. Unfortunately, it’s not just a simple 32-bit integer: it’s a so-called “synchsafe” integer.

A synchsafe integer is essentially a 28-bit integer with a 0 added after every 7 bits. It’s pretty weird, but luckily we have low level boolean logic at our fingertips: we’ll just break up the synchsafe integer into 4 bytes, then combine them back with the 8th bit of each byte removed.
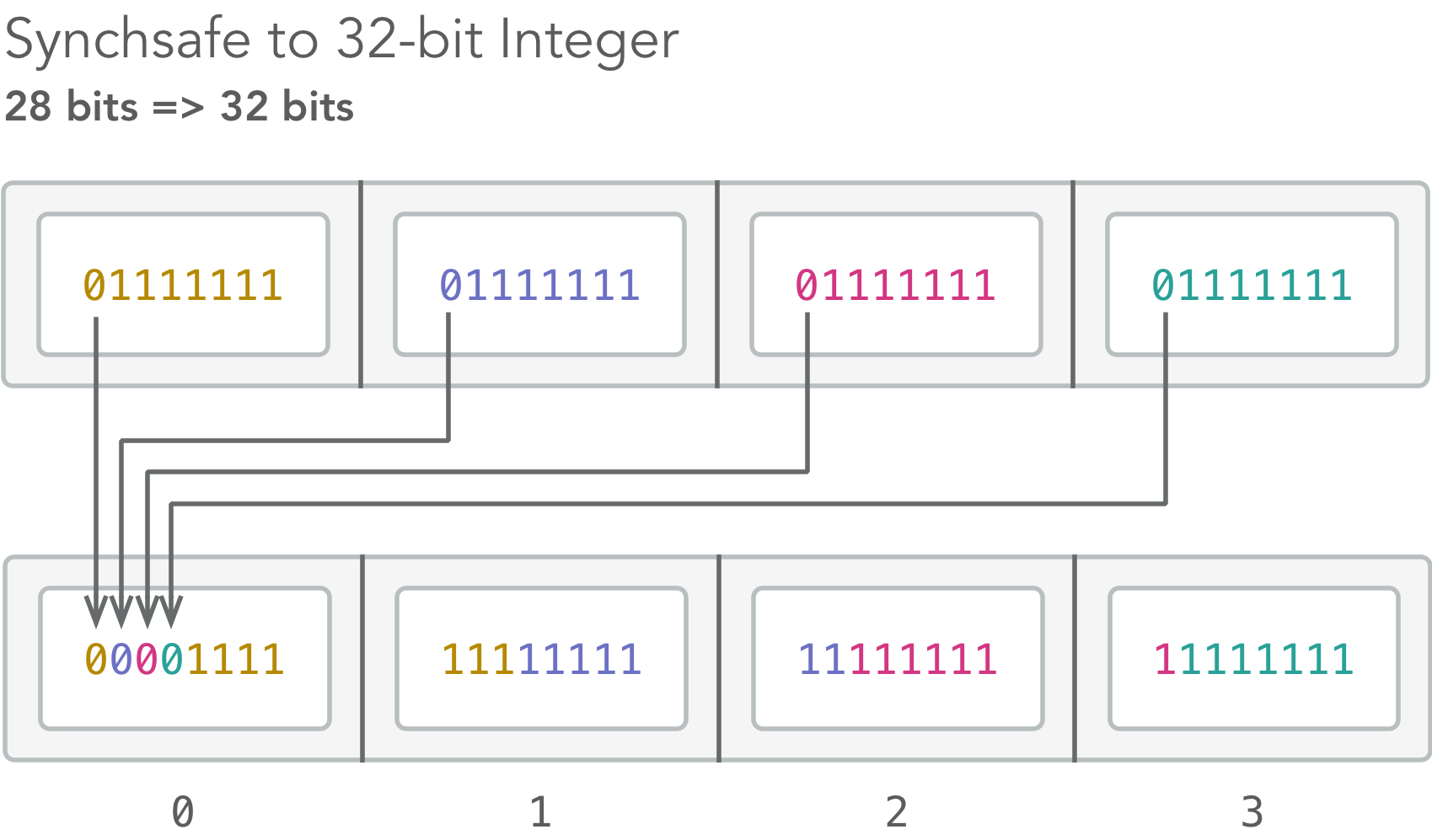
Why doesn’t the ID3 spec just use a regular 32-bit integer? MP3 was designed to be broadcast friendly, so audio players need to be able to play an MP3 from any given spot by watching for the next valid chunk of audio. Each chunk of audio begins with 11 bits set to 1 called the “frame sync.” By using synchsafe integers in the metadata section, this prevents interference with the “frame sync” mechanism. It’s still quite possible to have a sequence of 11 true bits elsewhere, but it’s fairly unlikely and players can easily perform correctness checks.
We’re done reading the 10-byte ID3 header, now it’s time to start looping through the “frames” that come next:
...
fs.readFile(file, (err, data) => {
...
let offset = HEADER_SIZE;
let id3Size = HEADER_SIZE + size;
while (offset < id3Size) {
}
});
ID3 metadata is stored in consecutive chunks called “frames.” Each frame represents a separate key-value pair, like the song’s title or composer. We can read them in by parsing one frame at a time, then skipping by the size of that frame to read the next one until we reach the end of the ID3 metadata. In a moment, we’ll write a function called decodeFrame() to handle this, but if it was implemented we could parse all the frames like such:
...
fs.readFile(file, (err, data) => {
...
while (offset < id3Size) {
let frame = decodeFrame(buffer, offset);
if (!frame) { break; }
console.log(`${frame.id}: ${frame.value.length > 200 ? '...' : frame.value}`);
offset += frame.size;
}
});
Parsing an ID3 Frame
Time to implement decodeFrame()! This function should return an object for one frame (key-value pair) structured like this:
{ id: 'TIT2',
value: 'Snöfrid (Snowy Peace)',
lang: 'eng',
size: 257 }
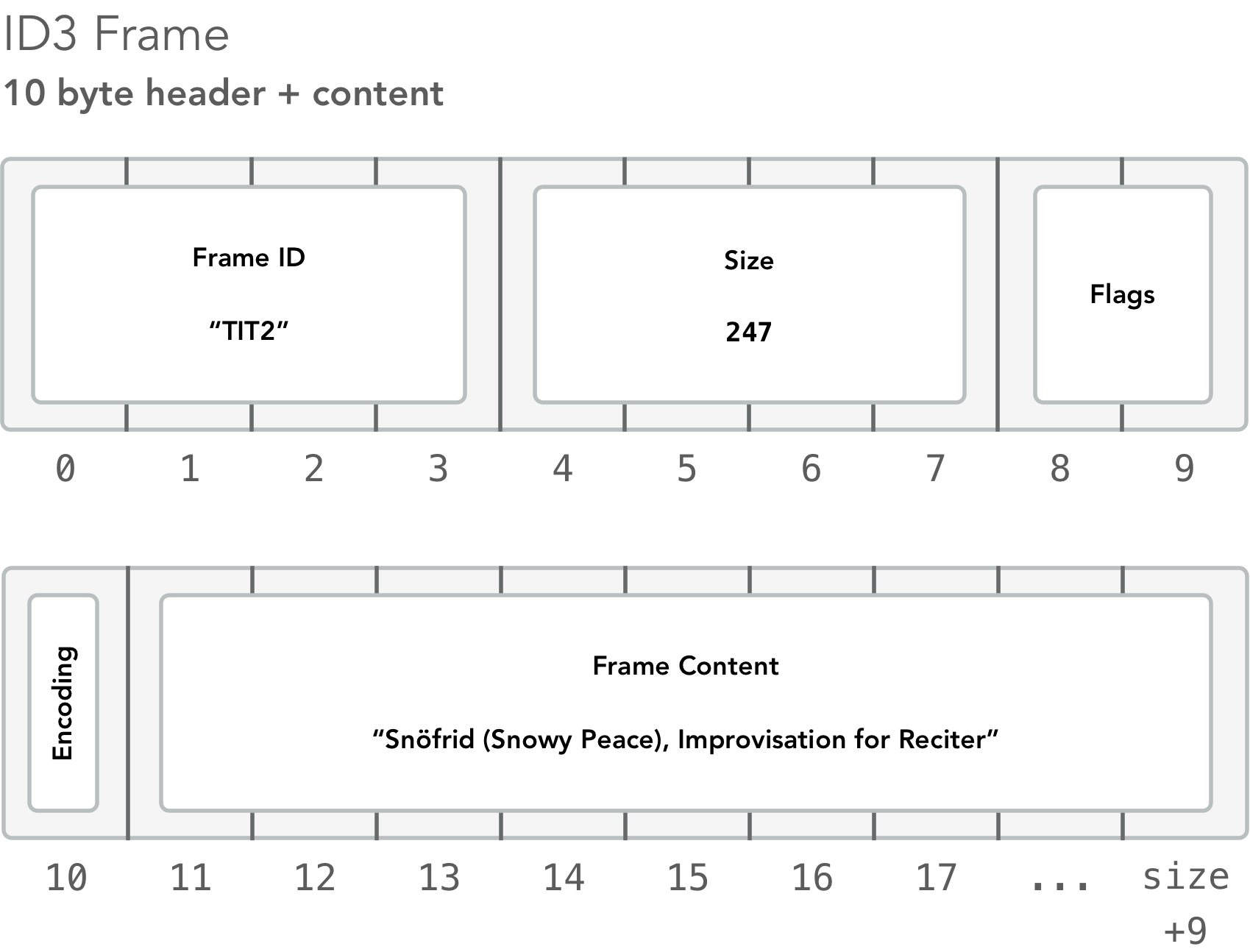
Each frame begins with a 10-byte header, then is followed by the frame’s actual content (the value).
...
let decodeFrame = (buffer, offset) => {
let header = new DataView(buffer, offset, HEADER_SIZE + 1);
if (header.getUint8(0) === 0) { return; }
};
After creating an 11-byte DataView (why 11 instead of 10? Hang tight) to inspect the frame’s header, we checked to make sure the first byte isn’t a zero, which would indicate there are no more frames to decode. Many MP3 encoders pad the ID3 metadata section with extra 0s (usually 2048 bytes of “null-padding”) to give audio players like iTunes room to insert more metadata without disturbing the rest of the file.
If the frame doesn’t start with zero, it’s safe to read in the first part of the header: the 4-byte frame ID. Frames are basically a single key-value pair, and the frame ID is the “key” of that pair:
...
let { TextDecoder } = require('text-encoding');
let decode = (format, string) => new TextDecoder(format).decode(string);
let decodeFrame = (buffer, offset) => {
...
let id = decode('ascii', new Uint8Array(buffer, offset, 4));
};
The 4-character frame ID is encoded as an ASCII string, like TIT2 (Title) or TCOM (Composer). To read in multiple bytes at a time, we need a different kind of view called a TypedArray. It’s not a constructor you’ll invoke directly, rather it refers to a class of fixed size homogeneous arrays. So to read in a list of unsigned 8-bit integers, we create a new Uint8Array typed array. If we wanted to read in signed (negative) numbers, we would use the Int8Array constructor instead, but that makes no sense for reading in ASCII bytes.
It’s not enough to fetch an array of 4 bytes—they need to be interpreted, or “decoded,” into a string. Frame IDs map directly to ASCII characters, so we invoked the TextDecoder constructor and its .decode() method to convert the byte array to a string.
Earlier we created an 11-byte DataView starting at the frame’s beginning. After the 4-byte frame ID comes the frame’s size:
...
let decodeFrame = (buffer, offset) => {
...
let size = header.getUint32(4);
let contentSize = size - 1;
let encoding = header.getUint8(HEADER_SIZE);
let contentOffset = offset + HEADER_SIZE + 1;
};
Bytes at indices 4–7 represent the rest of the frame’s size as an unsigned 32-bit integer. We don’t care about the 2 flag bytes which follow, so we are done decoding the frame header. But since it is only 10 bytes long, why did we read in 11? The first byte after the frame header (the 11th byte, index 10) specifies how the frame’s content is encoded, so in a way it is part of the frame header. To compensate for this “extra header byte,” we increased the contentOffset and decreased contentSize by 1.
This “encoding byte” can be set to 0, 1, 2 or 3, and maps to a text encoding like ascii or utf-8. This will help immensely, otherwise we might get gobbledygook if we mistakenly interpreted utf-8 text as ascii.
Decoding Strings
Finally, the frame’s real content begins at offset 11 of the frame. In addition to the encoding byte, some frames are also prefixed with a language descriptor:
...
const LANG_FRAMES = [
'USLT',
'SYLT',
'COMM',
'USER'
];
let decodeFrame = (buffer, offset) => {
...
let lang;
if (LANG_FRAMES.includes(id)) {
lang = decode('ascii', new Uint8Array(buffer, contentOffset, 3));
contentOffset += 3;
contentSize -= 3;
}
};
The language identifier is a 3 letter ASCII string, like eng or deu. Only certain frame types, like COMM (Comments), have a language identifier. Now onward to the real content!
...
const ID3_ENCODINGS = [
'ascii',
'utf-16',
'utf-16be',
'utf-8'
];
let decodeFrame = (buffer, offset) => {
...
let value = decode(ID3_ENCODINGS[encoding],
new Uint8Array(buffer, contentOffset, contentSize));
};
We finally grab the rest of the frame and decode the bytestream based on the encoding byte. For example, when encoding is set to 0 we interpret the frame’s content as ascii.
Now we just need to send everything back in a nice package:
...
let decodeFrame = (buffer, offset) => {
...
return {
id, value, lang,
size: size + HEADER_SIZE
};
};
There’s one catch: the frame size didn’t include the 10 byte frame header, so we added HEADER_SIZE to the returned size so the while loop can increment its offset by frame.size to hop to the next frame.
Time to run our script! Find an MP3 file and pass it to index.js. If it doesn’t print out ID3v2.3.0, try another MP3.
$ ./index.js fixtures/sibelius.mp3
ID3v2.3.0
PRIV: ...
TIT2: Snöfrid (Snowy Peace), Improvisation for Reciter, Chorus and Orchestra, Op. 29
TPE1: Lahti Symphony Orchestra, Jubilate Choir, Stina Ekblad and Osmo Vänskä
TALB: Sibelius: The Complete Symphonies - Karelia - Lemminkäinen - Violin Concerto
TCON: Classical
TCOM: Jean Sibelius
TPE3: Osmo Vänskä
TRCK: 38/43
TYER: 2011
COMM: Amazon.com Song ID: 222429669
TPE2: Lahti Symphony Orchestra and Osmo Vänskä
TCOP: 2011 Bis
TPOS: 1/1
APIC: ...
Hey look! We got the special Unicode characters to interpret correctly. Good ‘ol Osmo Vänskä (the conductor) gets his proper accents for free. If the parser was even one byte off, you’d get gobbledygook. Or if you mixed your ID3_ENCODINGS a bit, you might find yourself staring at byte order marks (BOM) and other gunk not-meant-to-be-seen-by-mortals:
ID3v2.3.0
PRIV: ...
TIT2: ǿnöfrid (Snowy Peace), Improvisation for Reciter, Chorus and Orchestra, Op. 29�
TPE1: ǿ﹌ahti Symphony Orchestra, Jubilate Choir, Stina Ekblad and Osmo Vänskä�
TALB: ǿibelius: The Complete Symphonies - Karelia - Lemminkäinen - Violin Concerto�
TCON: ǿ﹃lassical�
TCOM: ǿ﹊ean Sibelius�
TPE3: ǿ﹏smo Vänskä�
TRCK: ǿ︳8/43�
TYER: ǿ︲011�
COMM: ť湧䄀洀愀稀漀渀⸀挀漀洀 匀漀渀最 䤀䐀㨀 ㈀㈀㈀㐀㈀㤀㘀㘀㤀
TPE2: ǿ﹌ahti Symphony Orchestra and Osmo Vänskä�
TCOP: ǿ︲011 Bis�
TPOS: ǿ︱/1�
APIC: ...
Boom! You can download the finished code here.
Encore!
Thanks to the ArrayBuffer, DataView, TypedArray and TextDecoder APIs, you can easily decode binary file formats. Although dealing with file specs can be notoriously tricky, JavaScript’s console-friendly ways make it easy to practice exploratory programming to work out the kinks and off-by-one errors.
If you need a more extensive MP3 metadata parser for your binary libretti, you’ll probably want to use a library like JSMediaTags.
And there you have it! A masterful binary performance of Snöfrid by the JavaScript Symphony Orchestra, conducted by Node.js.
If you choose me, then you choose the tempest.
For the hardy poems of the hero’s life say:
Draw your sword against vile giants,
bleed valiantly for the weak,
deny yourself with pleasure, never complain,
fight the hopeless fight and die nameless.
That is the true heroic saga of life.—Viktor Rydberg